This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Overview
Overview of the MongoDB Operator
MongoDB Operator is an operator created in Golang to create, update, and manage MongoDB standalone, replicated, and arbiter replicated setup on Kubernetes and Openshift clusters. This operator is capable of doing the setup for MongoDB with all the required best practices.
Architecture
Architecture for MongoDB operator looks like this:-

Purpose
The aim and purpose of creating this MongoDB operator are to provide an easy and extensible way of deploying a Production grade MongoDB setup on Kubernetes. It helps in designing the different types of MongoDB setup like - standalone, replicated, etc with security and monitoring best practices.
Supported Features
- MongoDB replicated cluster setup
- MongoDB standalone setup
- MongoDB replicated cluster failover and recovery
- Monitoring support with MongoDB Exporter
- Password based authentication for MongoDB
- Kubernetes’s resources for MongoDB standalone and cluster
1 - MongoDB Overview
An overview of MongoDB database, types of setup and architecture design
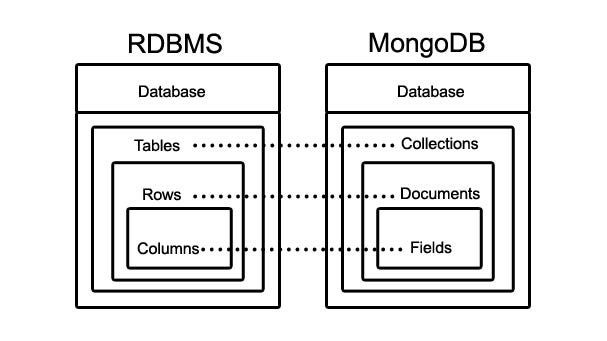
MongoDB is an open source, cross platform, document oriented NoSQL database that stores data in the form of documents and collections. A document is nothing but a record, that contains all information about itself. A group of documents, is called a collection.
A document can contain a number of fields (value), regarding the details of the record. One document size can be different from the other as two different documents can store varied number of fields. Every field (value) has an associated key mapped to it. The field can be of any data type like the general text, number, etc. A field can also be a link to another document or arrays. MongoDB uses BSON (binary encoding form of JSON), to include additional data types like date, that is not compatible with JSON.
Features
- Scalability:- MongoDB is a specialized database for BigData processing. It can contain large volumes of data, therefore making it highly scalable.
- Flexibility:- MongodB is schema-less which means it doesn’t enforce relations between fields, rather allows the storage of values of any data type, in a stream.
- Sharding:- Sharding is an interesting and a very powerful methodology in MongoDB. MongoDB allows distribution of data onto several servers, as opposed to a single server.
- Data replication and recovery:- MongoDB provides specialized tools for data replication, as a backup, in times of any system failure.
- High Performance and Speed:-
MongoDB supports different features like dynamic ad-hoc querying, indexing for faster search functionality, tools like Aggregation pipeline for aggregation queries etc.
MongoDB Database
2 - MongoDB Setup
A detailed guide for designing the setup of MongoDB architecture
MongoDB is a NoSQL document database system that scales well horizontally and implements data storage through a key-value system. MongoDB can be setup in multiple mode like:-
- Standalone Mode
- Cluster replicated mode
- Cluster sharded mode
Standalone Setup
Just like any database mongodb also supports the standalone setup in which a single standalone instance is created and we setup MongoDB software on top of it. For small data chunks and development environment this setup can be ideal but in production grade environment this setup is not recommended because of the scalability and failover issues.

Replicated Setup
A replica set in MongoDB is a group of mongod processes that maintain the same data set. Replica sets provide redundancy and high availability, and are the basis for all production deployments.
These Mongod processes usually run on different nodes(machines) which together form a Replica set cluster.

Sharded Setup
Sharding is a method for distributing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations.
- Shard: Each shard contains a subset of the sharded data. Each shard can be deployed as a replica set to provide redundancy and high availability. Together, the cluster’s shards hold the entire data set for the cluster.
- Mongos: The mongos acts as a query router, providing an interface between client applications and the sharded cluster.
- Config Servers: Config servers store metadata and configuration settings for the cluster. They are also deployed as a replica set.